Preços de Ações como um Objeto DataFrame
O uso de dados financeiros online gratuitos está restrito na sua distribuição. Então, em vez de ter exemplos de dados disponíveis no site aqui, eu mostrarei a você como obtê-los nos recursos online. Nos exemplos tenho usado os dados obtidos da mesma maneira. Especificamente, usarei dados do Yahoo! FinanceR.
Pesquisadores mais sofisticados tem a tendência de automatizarem o processo obtendo dados online. Existem realmente várias bibliotecas livres de funções que permitem você acessar sites como o Yahoo! FinanceR. Mas devemos lembrar que estes sites podem mudar sua política de acesso sem ter a necessidade de consultar ou informar os usuários. Afinal, eles pagam pelos dados e nós não. Realmente, o Yahoo! FinanceR e o Google FinanceR, outro site popular, pararam o acesso à API por robôs. robôs. É um pouco tedioso se você quiser testar suas ideias com muitas ações, mas para fins de ilustração, os dados baixados manualmente são mais que suficientes.
Vá ao website Yahoo! FinanceR para baixar os preços históricos da Tesla, Inc. Eu usarei o lote automaker como um exemplo neste capítulo. Aqui estão os passos:
1. Na barra de pesquisa da página principal do Yahoo! FinanceR digite na caixa da lupa TSLA.
2. na página principal da ação TSLA, clique na guia Historical Data:

3. Mude o Time Period e a Frequency para o frame de tempo desejado. Garanta que você apertou o botão Apply antes do seu próximo movimento. Eu usarei os cincos períodos anuais entre Jun/06/2017 e Jun/06/2022 com frequência mensal.
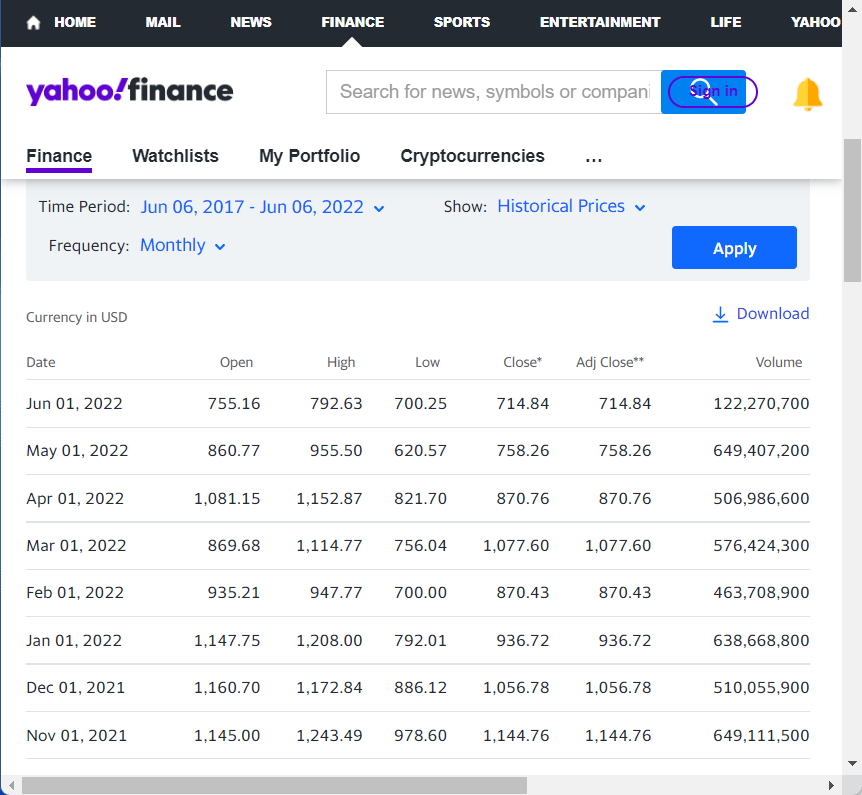
4. Clique em Download Data.

O arquivo de dados está no formato csv e armazenado no seu diretório download.
Mova-o para o seu diretório de trabalho Python e você está pronto para continuar.
Automatizando o carregamento de dados financeiros
Primeiramente precisamos instalar as bibliotecas necessárias ao trabalho em Finanças no Python. São elas:
Pandas - Ela nos oferece a poderosa estrutura de dados chamada data frame. Com o Pandas podemos gerenciar nossos dados de forma semelhante às tabelas SQL ou planilhas de Excel.
Pandas-Datareader - É uma biblioteca adicional que vamos usar para carregar dados financeiros da internet. Ela carrega os dados de APIs em data frames.
Matplotlib - Usamos para visualizar nossos dados e nossos modelos. Com ela podemos escolher entre uma variedade de diferentes tipos de plotagem e estilos.
MPL-Finance - Trabalha em conjunto com o Matplotlib e nos permite usar visualização especial para finanças, principalmente, para traças gráficos candlestick.
NumPy - É uma biblioteca fundamental para álgebra linear, e permite de forma, eficiente e eficaz, trabalharmos com matrizes.
Scikit_Learn - Oferece um monte de diferentes modelos clássicos e tradicionais e machine learning.
BeautifulSoup4 - É uma poderosa biblioteca de scraping web. Vamos usá-la para extrair dados financeiros de arquivos HTML.
Quanto a instalação das citadas bibliotecas:
pip install pandas pip instal pandas_datareader pip install matplotlib pip install mplfinance pip install scikit-learn pip install beautifulsoup4
Uma vez instaladas as citadas bibliotecas, vamos começar dando uma olhada em como carregar automaticamente os dados financeiros em nosso script.

Com isso importamos o módulo data da biblioteca pandas_datareader com a alias (apelido) web. Este módulo data será usado para obter nossos dados do Yahoo Finance API. Estamos, também, importando o módulo datetime de maneira que possamos especificar time frames. E para fazer isso, usamos a função datetime:

Aqui definimos uma data de início e uma data de término. Esse é o nosso prazo. Quando carregamos os dados, queremos todas as inscrições a partir do 1º de janeiro de 2017 até o dia 1º de janeiro de 2022. Alternativamente, também podemos usar a função datatime.now, para especificar o presente como a data final.
end = dt.datatime.now()
O próximo passo é definir um data frame e carregar os dados financeiros nele. Para isso precisamos saber quatro coisas. Primeiro: o símbolo do ticker da ação que queremos analisar. Segundo: O nome da API que queremos receber os dados (aqui é o yahoo). E por último: a data de início e término.
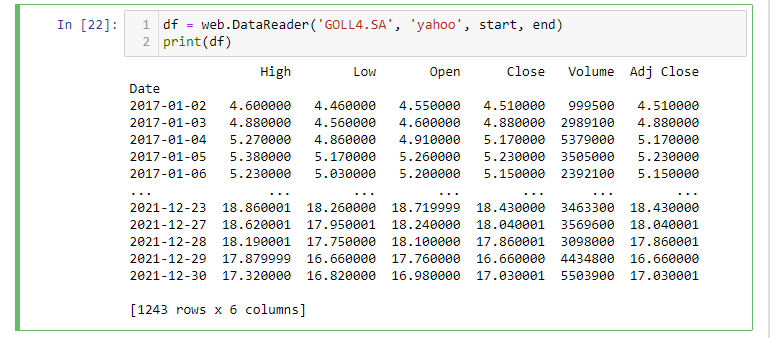
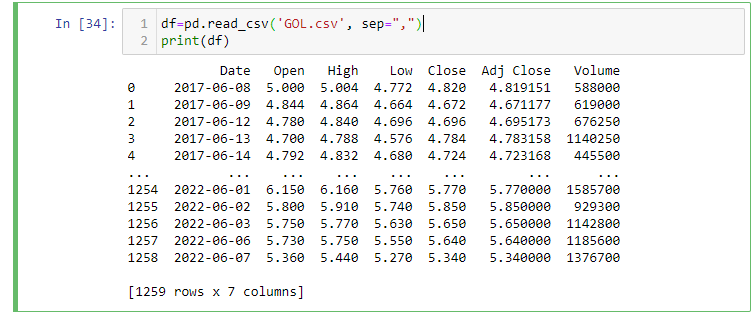
Temos um dataframe com 1.243 linhas e 6 colunas.
Estamos criando, portanto, uma instância do DataReader e passamos os quatro parâmetros. Nesse caso, estamos usando o Yahoo FinanceR API, a fim de obter os dados financeiros da GOL (GOLL4.SA) da data inicial (2017,1,1) até a data final (2022,1,1).
Para visualizarmos os nossos dados baixados, podemos imprimir como feito na célula de código anterior.
Aviso: Às vezes, a API do Yahoo Finance não responde e você terá uma exceção. Neste caso, seu código não é o problema e você pode resolver o problema esperando um pouco e tentando novamente.
Como você pode ver, agora temos um data frame (quadro de dados) com todas as entradas desde a data de início até a data de término. Observe que temos várias colunas aqui, e não apenas o preço de fechamento das ações do respectivo dia. Vamos dar uma olhada rápida nas colunas individuais e seu significado.
Open - Esse é o preço que as ações tinham quando os mercados abriram naquele dia.
Close - Esse é o preço que as ações tinham quando os mercados fecharam naquele dia.
High - Esse é o maior preço que as ações tiveram naquele dia.
Low - Esse é o menor preço que as ações tiveram naquele dia.
Volume - Quantidade de ações que mudaram de mãos (negociadas) naquele dia.
Adj. Close - O valor de fechamento ajustado que leva em consideração coisas como ações se dividem.
Leitura de Valores Individuais
Uma vez que nossos dados estão armazenados em um data frame Pandas, podemos usar a indexação que já conhecemos, para obter valores individuais. Por exemplo, só poderíamos imprimir os valores de fechamento.
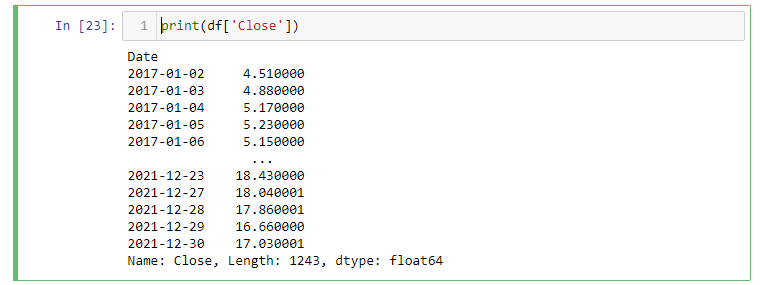
Também, podemos ir adiante e imprimir o valor de fechamento de uma data específica que estivermos interessados nela. Isto é possível porque a data é nossa coluna índice.

Mas, podemos usar, também, a indexação simples para acessar certas posições:

Aqui imprimimos o preço de fechamento da quinta entrada.
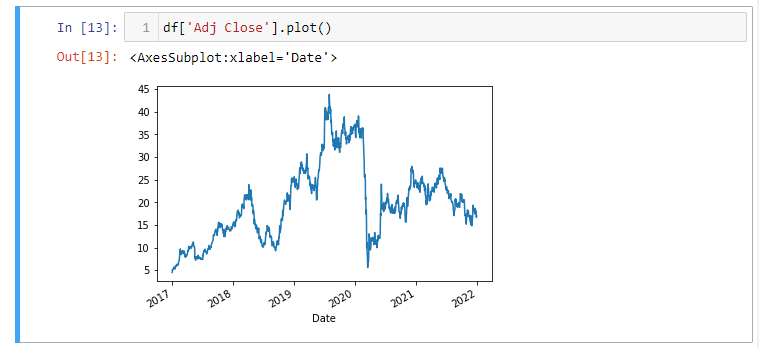
Podemos também plotar as séries de preços de ações:
Ainda mais, pode-se criar uma coluna no DataFrame para armazenar séries de retorno da GOLL4.SA ou usar a função embutida do Pandas .pct_change():
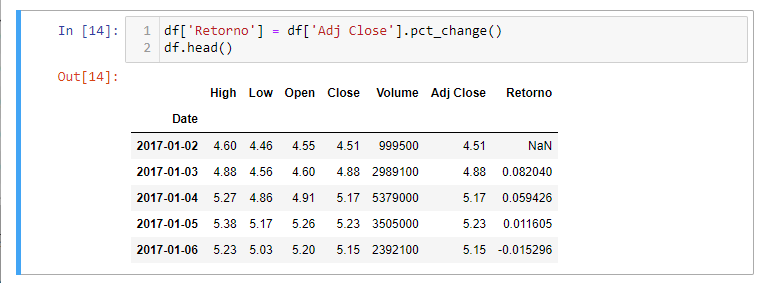
Quando se aplica a .pct_change(), você precisa se garantir que as datas estejam em ordem crescente. Quando movemos os preços para os retornos, perdemos um ponto de dados. O NaN, como na primeira linha dos dados, pode tornar os cálculos posteriores problemátifcos. Podemos retirar essa linha com:

Vejam como ficam agora os 5 primeiros dados:
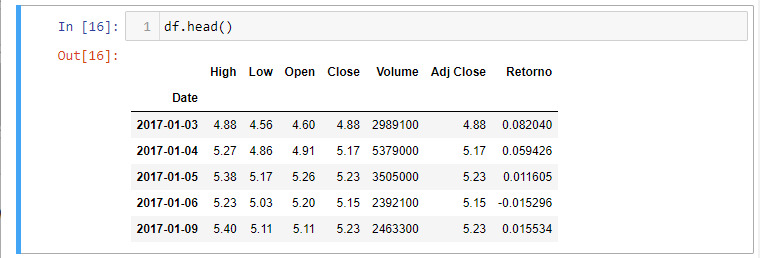
Salvando e Carregando Dados
Com a biblioteca Pandas podemos agora salvar os dados financeiros num arquivo, de modo que não temos que requerer ele da API, toda vez que rodamos o script. Isto apenas custa tempo e recursos. Para isso podemos usar um punhado de formatos diferentes.
CSV
Podemos salvar o nosso data frame Pandas num arquivo de extensão CSV:

Aqui estamos separando nossos dados por vírgula.
Se quisermos fazer a leitura desse arquivo csv:
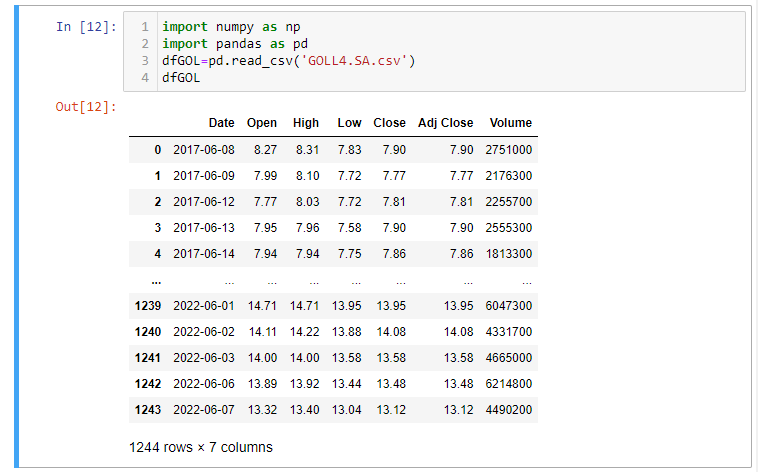
Para isso, nomeamos o nosso data frame como dfGOL.
EXCEL
Para colocarmos, se quisermos, nossos dados numa planilha Excel, podemos usar a função to_excel:

Quando abrirmos esse arquivo em Excel, ele se parecerá com isso:
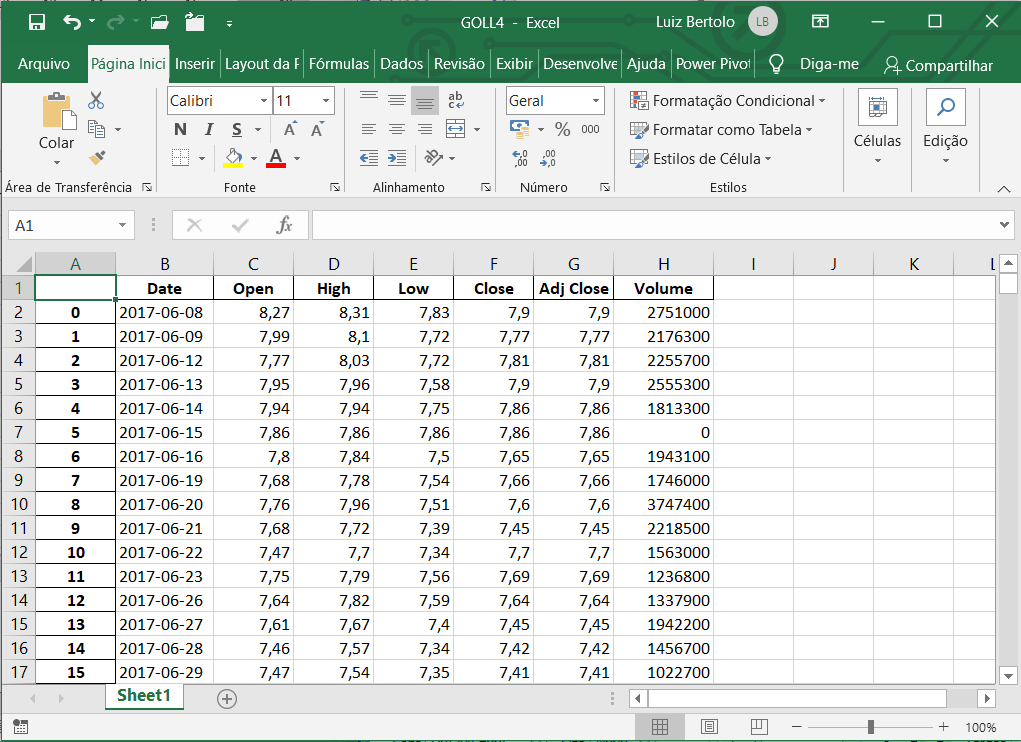
Podemos agora analisar nosso data frame e, ainda mais, no ambiente de uma planilha Excel
HTML
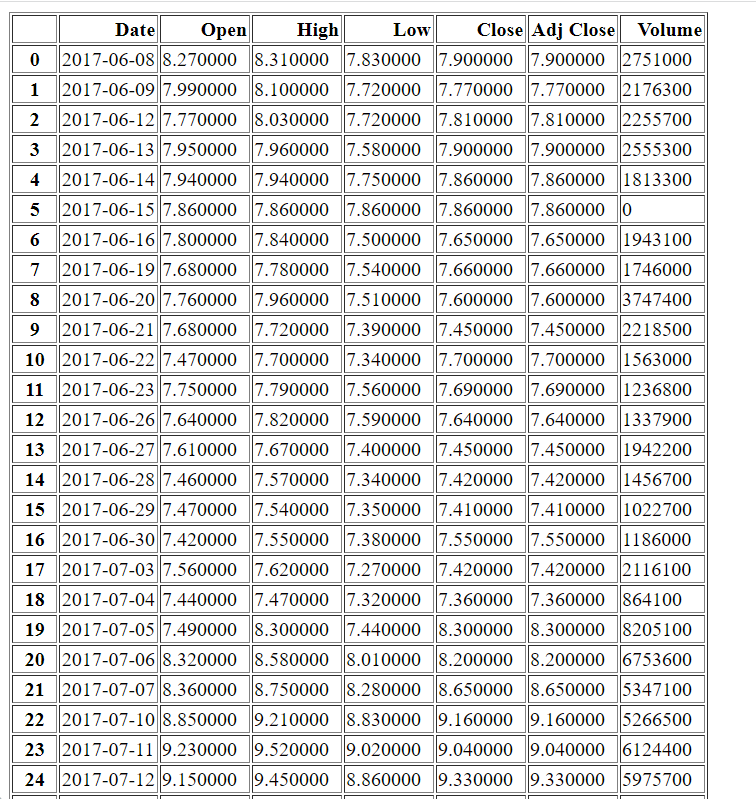
Se, por alguma razão, precisarmos que os nossos dados sejam mostrados em browsers, podemos, também, exportá-los em arquivos HTML.

O resultado é uma simples tabela HTML:
JSON
Finalmente, se estivermos trabalhando com JavaScrit ou apenas quisermos os dados nesse formato, podemos usar o JSON. Para isso, usamos a função to_json:

Carregando Dados de Arquivos
Para cada formato de arquivo, também temos uma função de carregamento ou leitura respectiva. Às vezes encontraremos dados em formato HTML, às vezes no formato JSON. Com Pandas podemos ler os dados facilmente.
df = pd.read_csv("GOL.csv", sep=",")
df = pd.read_excel("GOL.xlsx")
df = pd.read_html("Gol.html")
df = pd.read_json("Gol.json")
Por exemplo, para ler os dados de um arquivo csv: